My research is in (multi-agent) reinforcement learning spanning topics such as team formation, hierarchical planning, and test-time adaptation. I’m passionate about applying the fundamental methods I develop in Robotics. Previously, I did my bachelor’s in Computer Science at Amirkabir University of Technology.
Variational option discovery methods in multi-agent reinforcement learning (MARL) are powerful tools for hierarchical control, especially in settings with sparse rewards. However, these methods often struggle with a critical challenge: they tend to learn localized options that explore only a small portion of the state space. This issue stems from the difficulty of encouraging widespread exploration while maximizing a variational lower bound inherent in these frameworks. We solve this by proposing the Multi-Agent Variational Covering Option Discovery (MAVCOD) algorithm. Our core contribution is the Connectivity-Aware Replay Buffer Graph (CARBG), a novel and efficient data structure that dynamically tracks approximate bounds for connectivity of the individual and joint state-transition graphs. By using these connectivity bounds as intrinsic rewards, MAVCOD explicitly guides agents to discover covering options that bridge disparate regions of the state space. We provide theoretical insights on how maximizing our intrinsic rewards minimizes the expected cover time of the state-transition graphs. Empirically, we demonstrate on challenging sparse-reward benchmarks that MAVCOD significantly outperforms a state-of-the-art baseline. Furthermore, state visitation heatmaps visually confirm that our method achieves substantially better exploration.
Team formation and the dynamics of team-based learning have drawn significant interest in the context of Multi-Agent Reinforcement Learning (MARL). However, existing studies primarily focus on unilateral groupings, predefined teams, or fixed-population settings, leaving the effects of algorithmic bilateral grouping choices in dynamic populations underexplored. To address this gap, we introduce a framework for learning two-sided team formation in dynamic multi-agent systems. Through this study, we gain insight into what algorithmic properties in bilateral team formation influence policy performance and generalization. We validate our approach using widely adopted multi-agent scenarios, demonstrating competitive performance and improved generalization in most scenarios.
Quantum computing, especially quantum annealing, holds promise for tackling intricate optimizationchallenges. However, its practical implementation confronts limitations like restricted hardwareconnectivity. This report describes our efforts to augment the performance of quantum annealersin solving the maximum clique problem through traditional graph decomposition techniques andmachine learning methodologies. Building on the DBK decomposition algorithm proposed by Pelofske et al. [2021], we propose a new RL-enhanced decomposition step, and two learning-assisted vertex selection methods (imitation learning and reinforcement learning). Preliminary experiments on medium-scale synthetic datasets show considerable improvements. All relevant data and code pertaining to this research are openly accessible on our Github repository.

An advanced line follower robot that uses a camera and OpenCV for image processing to detect lines and shapes of different colors.
An AI project on community detection in networks using Genetic Algorithm and Cuckoo Search, including locus-based representation and modularity as a fitness function.

A deep learning project to detect Iranian paper money for visually impaired individuals, using TensorFlow Lite and transfer learning on MobileNet.
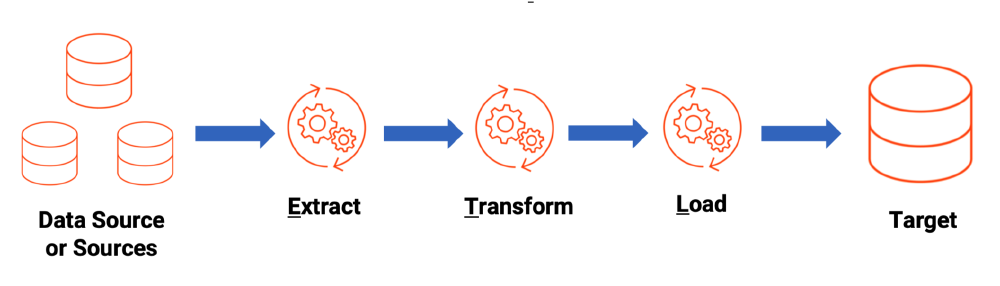
A three-phase project for a database course, including database design, ETL pipeline creation, and a ’time machine’ feature for database restoration.

A combinatorial optimization project to schedule mid-term exams for the MCS department at Amirkabir University of Technology, using mathematical modeling and GAMS.
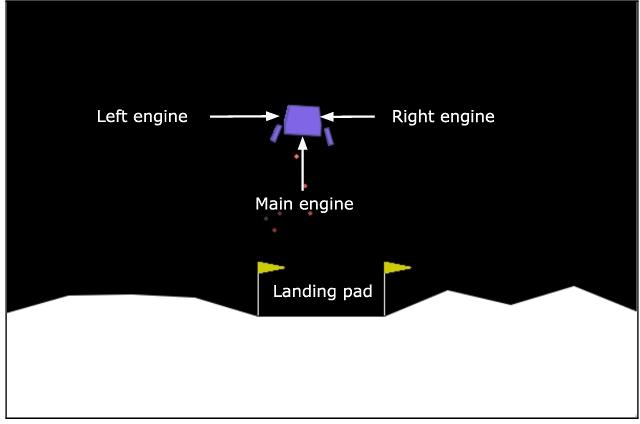
An improvement on a reinforcement learning project, using Expected Sarsa and a neural network to play Lunar Lander games, trained with Keras and TensorFlow.

A shooting simulator game created for a school fair that uses a laser-equipped toy gun and an IP camera for scoring.

A line follower robot developed during junior high school using an AVR microcontroller, designed with Proteus, and programmed with Bascom.
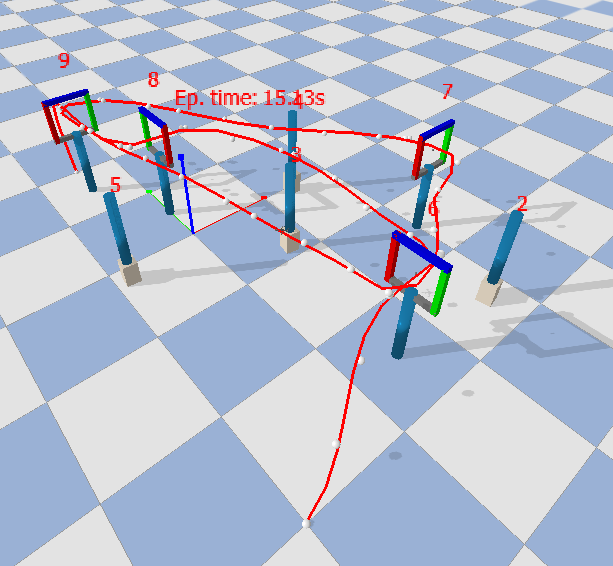
This project implements an enhanced 3D RRT* (Rapidly-exploring Random Tree Star) algorithm to plan drone trajectories through a sequence of gates while avoiding obstacles. The planner is adapted for realistic racing conditions, supporting both take-off and landing phases and fine-grained path smoothing for controller execution. Key innovations include sampling biases, strict collision checking during rewiring, and customized handling of drone kinematics (speed profiles, banking angles).

This repository contains the capstone project for the Coursera Modern Robotics Specialization (Course 6). The project implements autonomous mobile manipulation for a KUKA youBot to pick and place objects using trajectory planning, odometry, and feedback control.
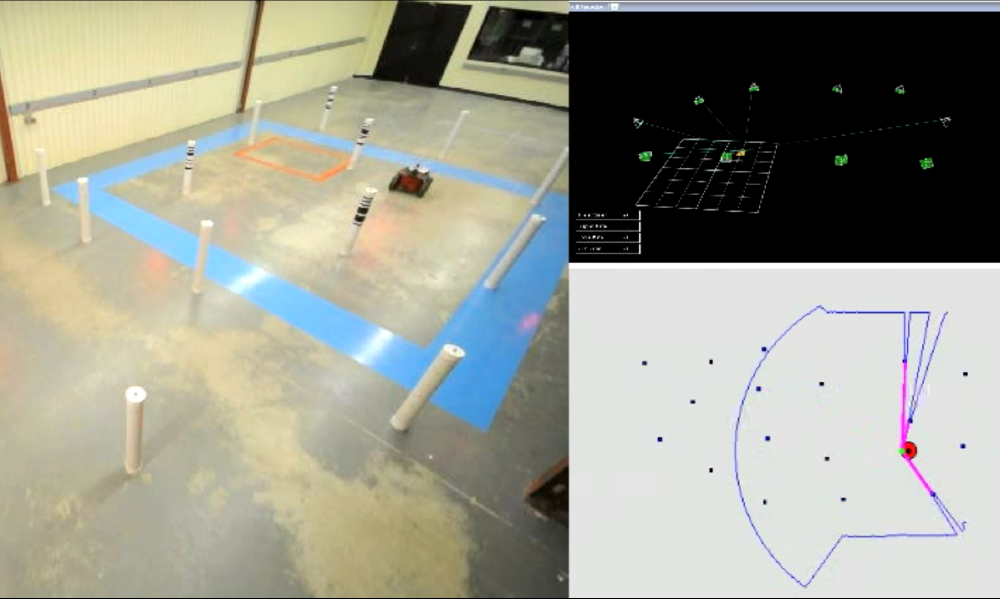
This repository contains a reference implementation of an Extended Kalman Filter (EKF) for planar mobile robot state estimation. The EKF estimates the robot pose (x, y, θ) using odometry/control inputs and range–bearing measurements to known landmarks.
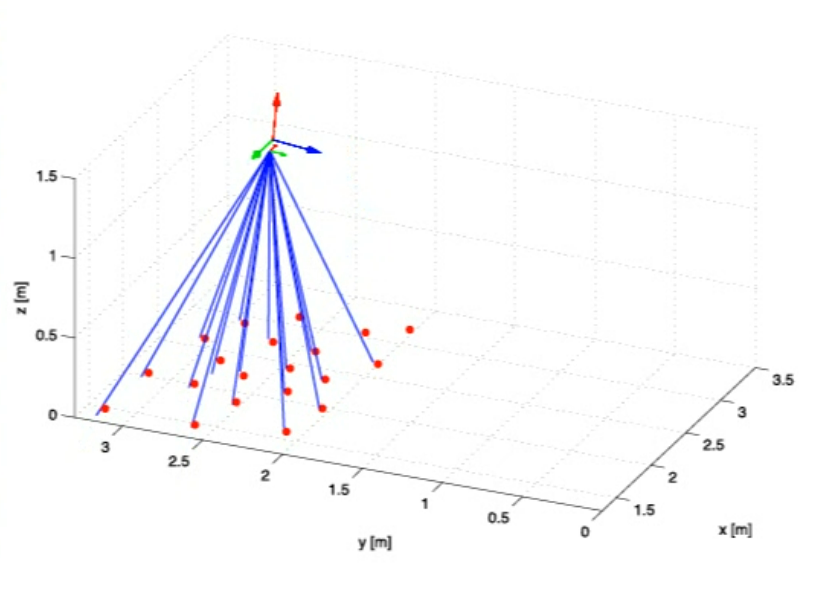
The goal is to estimate the full 3D position and orientation trajectory of a sensor head as it moves through space. The solution fuses measurements from two different sensors—a stereo camera and an Inertial Measurement Unit (IMU)—using the Gauss-Newton method.

This projects introduces a comprehensive framework for training autonomous drone swarms in pursuit-evasion tasks using multi-agent reinforcement learning. The work’s central innovation is a ‘progressive scenario architecture’, a six-tier system designed to systematically increase coordination complexity. This tiered approach guides agents from basic trajectory-following of static goals to the cooperative capture of intelligent and evasive targets. By bridging theoretical coordination strategies with realistic quadrotor physics and aerodynamics , this progressive system successfully validates that agents can learn sophisticated, cooperative behaviors in complex, multi-constraint environments.
2023-2028 Ph.D in Reinforcement Learning and RoboticsCGPA: 3.91 out of 4Extracurricular Activities:
Thesis:Test-Time Adaptive Team-Aware Hierarchical Planning in Cooperative Multi-Agent Reinforcement Learning Supervisor:Prof. Chi-Guhn Lee | ||||||||||||||
2019-2023 B.Sc. in Computer ScienceCGPA: 19.57 out of 20Taken Courses:
Accomplishments:Ranked 1st in the class of 2023 among 82 students. | ||||||||||||||
Higher Secondary School CertificateCGPA: 19.97 out of 20Extracurricular Activities:
Accomplishments:Ranked 434 out of 164,278 students (top 0.3%) in the Mathematics field in the Iranian National University Entrance Exam. Patent:No. 13965014000301156 - “Circular Ruler for Measuring Angles, Drawing Circles, and Linear Measurement with Integrated Set Square Functionality” |
